GRPO Ensembles Fine-Tuning ve Özelleşmiş Ödül Fonksiyonları Çalışması

Büyük Dil Modellerini (LLM) belirli bir amaca uygun hale getirmek (alignment) günümüz yapay zeka mühendisliğinin en zorlu konularından biri. Yıldız Teknik Üniversitesi'ndeki Kollektif Öğrenme dersi kapsamında, bu problemi çözmek için kullanılan modern yöntemlerden biri olan GRPO (Group Relative Policy Optimization) üzerine derinlemesine bir çalışma yapma fırsatı buldum.
Amacım, "ytu-ce-cosmos/turkish-gpt2-large-750m-instruct-v0.1" modelini, bilgi ezberlemekten ziyade mantıksal çıkarım yapmaya teşvik edecek çeşitli ödül fonksiyonları (reward functions) ile eğitmek ve bu modelleri birleştirerek bir Reward Ensemble oluşturmaktı.
Bu yazıda, bu süreçte karşılaştığım donanım limitlerini, tasarladığım ödül fonksiyonlarını ve bir mühendislik çözümü olarak LoRA adaptörlerini nasıl manuel olarak birleştirdiğimi (ensemble) anlatacağım.
1. Veri Hazırlığı ve Prompt Mühendisliği
İlk adım, modelin mantıksal düşünme yeteneğini ölçebileceğimiz doğru veriyi bulmaktı. HuggingFace üzerindeki alibayram/turkish_mmlu veri setini temel aldım. Ancak tüm veriyi kullanmak yerine, 786 konu içerisinden belirli anahtar kelimelere göre filtreleme yaparak, sadece mantıksal düşünme gerektiren yeni bir alt veri seti oluşturdum.
Eğitim için 1000, test için ise 500 soru-cevap çifti ayırdım. Soruların cevapları beş şıklıydı. Modelin yapıyı anlayabilmesi için veriyi şu spesifik prompt formatına dönüştürerek modeli besledim:
Soru: {soru}
Seçenekler: {seçenekler}
Cevap:2. Mühendislik Darboğazı: VRAM Sınırları ve LoRA Çözümü
Eğitim aşamasına geçtiğimde, LLM dünyasının o meşhur duvarına çarptım: VRAM yetersizliği. Modeli doğrudan (full fine-tuning) eğitmeye çalışırken defalarca bellek sınırlarına takıldım.
Bu donanım kısıtını aşmak için LoRA (Low-Rank Adaptation) kullanmaya karar verdim. Eğitimi soru başına 4 cevap üretecek şekilde, 100 adımlı birer epoch olarak yapılandırdım. LoRA ve GRPO konfigürasyonları ile oynayarak eğitimi hızlandırmaya ve hesaplama maliyetini olabildiğince agresif bir şekilde düşürmeye çalıştım.
3. Ödül Fonksiyonlarının Tasarımı (Reward Functions)
GRPO'nun standart ödül fonksiyonu genellikle sadece "doğruluk" ve istenen "formata" uyum üzerine kuruludur. Ben modeli farklı davranışlara itmek için bu standarta ek olarak 4 alternatif ödül fonksiyonu daha tasarladım. Toplamda 5 farklı model eğittim:
- Standart: Yalnızca cevabın doğruluğuna ve formatına puan veren temel yapı.
- Akıl Yürütme (Reasoning): Modelin cevaplarını açıklamaya teşvik etmek için içerikte "çünkü", "bu nedenle", "yani", "sonuç olarak" gibi bağlaçların arandığı ve ödüllendirildiği fonksiyon.
- Cezalandırma (Penalty): Modelin tereddütlü cevaplardan kaçınması için "sanırım" ve "tahminen" gibi kelimeleri kullanmasını cezalandıran (negatif ödül) fonksiyon.
- XML Yapılandırma: Modelin daha yapısal ve düzenli düşünmesini sağlamak için, cevabı
<dusunce>.*?</dusunce>.*Cevap:gibi spesifik XML desenlerine uydurmaya zorlayan fonksiyon. - Uzun Cevaplara Teşvik: Modelin cevabını belli bir uzunluğun üzerinde tuttuğunda (anlamı koruduğu varsayımıyla) ekstra puan aldığı fonksiyon.
4. Bir Mühendislik Çözümü: Manuel LoRA Ensemble
Eğitilen bu farklı modellerin yeteneklerini tek bir potada eritmek istedim. Ancak LoRA kullandığım için elimde ana modelin farklı versiyonları değil, farklı görevlere göre optimize edilmiş adaptörler (adapters) vardı.
Standart araçlarla (örneğin MergeKit) bu adaptörleri doğrudan lineer olarak birleştirmek mümkün olmuyordu. Bu problemi aşmak için, eğitilen adaptörlerin ağırlık matrislerinin manuel olarak ortalamalarını alarak kendi "Ensemble Adapter" yapımı oluşturdum.
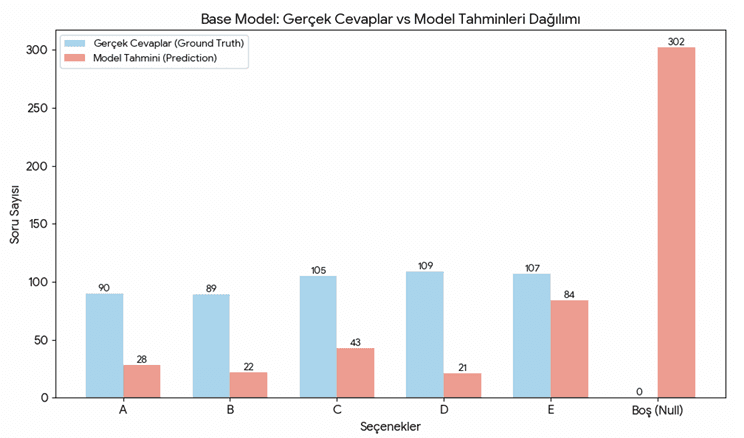
5. Değerlendirme ve Post-Mortem: Neden %20'nin Altında Kaldık?
Eğitilen 5 model ve oluşturduğum 1 Ensemble modeli, ayırdığım 500 test sorusu ile test ettim. Sonuçlar (Accuracy/Doğruluk oranları) ilk bakışta düşük görünse de, LLM eğitim dinamikleri açısından harika çıktılar sundu:
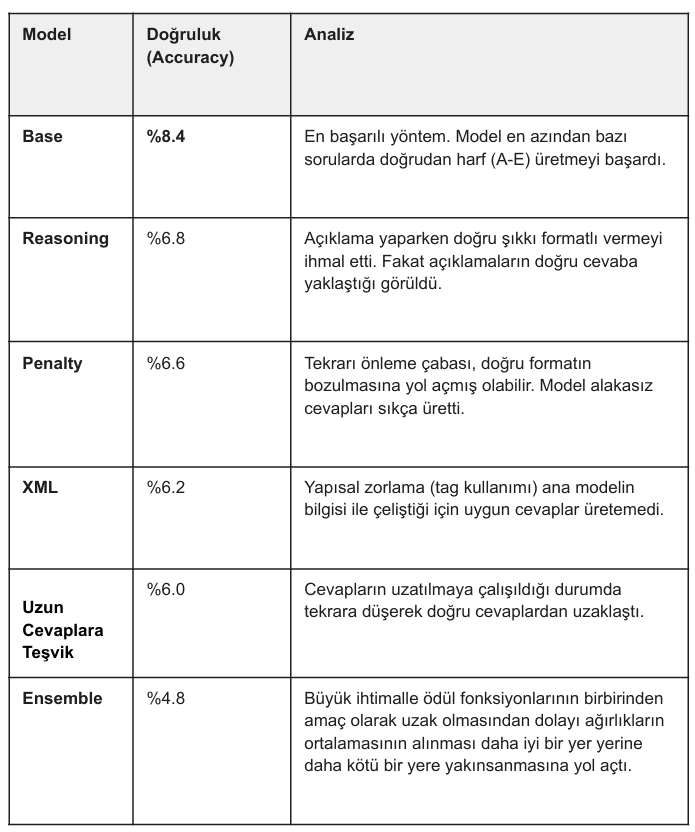
Base Model Dağılım Grafiği: Aşağıdaki grafikte Base modelin gerçek cevaplar (Ground Truth) ile tahminleri (Prediction) arasındaki dağılımı görebilirsiniz. Modelin cevap formatına uyamadığı durumlar en sağdaki "Boş (Null)" sütununda açıkça görülüyor.
Çıkarımlar
Modellerin başarısının %20'den düşük olması ve rastgele cevap vermekten bile kötü performans sergilemesinin arkasında yatan temel mimari ve sistemsel nedenleri şöyle özetleyebilirim:
- Agresif Maliyet Optimizasyonu: VRAM limitleri nedeniyle hesaplama maliyetini aşırı düşürme çabam (düşük epoch ve adım sayısı), modelin hedeflenen davranışı tam olarak öğrenememesine (underfitting) neden oldu.
- Format Çakışması: Modeller çeşitli sorularda mantıken doğru cevabı yakalasa da, benden beklenen katı
Cevap:{a, b, c, d, e}formatına uyum sağlayamadığı için sistem tarafından "yanlış/boş" olarak değerlendirildi. Özellikle XML ve Reasoning modellerinde bu durum çok belirgindi. - Zıt Hedefli Ensemble: Ensemble modelinin en düşük skoru alması çok doğal bir sonuçtu. Birbirinden yapıca ve amaçça çok farklı (biri uzun cevap isterken, diğeri spesifik kelimeleri yasaklayan) ödül fonksiyonlarının ağırlık ortalamasını almak, modelin kafasını karıştırarak ağırlıkları optimum olmayan bir noktaya sürükledi.
Sonuç
Bu proje, bir LLM'i RLHF/GRPO mantığıyla eğitirken sadece ödül fonksiyonunu yazmanın yetmediğini; donanım bütçesinin (compute budget), prompt mühendisliğinin ve değerlendirme (evaluation) metriklerindeki format esnekliğinin ne kadar kritik olduğunu bana yaşayarak öğretti.